
Clinical Practice Guidelines: Time Needed to Treat, Sagas, and The Patient Journey


In a paper titled Guidelines should consider clinicians’ time needed to treat [1] , Johansson et al. write:
“A simulation study applying all guidelines for preventive care, chronic disease care, and acute care to a panel of 2500 adults representative of the US population estimated that US primary care physicians would require up to 27 hours a working day to implement (and document) all applicable guidelines. To fully satisfy only the recommendations from the US Preventive Services Task Force would require 7.4 hours a day.”
The paper correctly points out that the availability of tools and technology is one of the factors that affect the time needed to treat (TNT). Most of the headline-grabbing news about AI in healthcare have been in medical imaging applications using Deep Learning and how ChatGPT is going to revolutionize medicine. However, real-world clinical practice involves complex decisions and processes spanning space and time and crossing organizational and disciplinary boundaries.
Toward a System-level Approach to AI Implementation in Healthcare
Concordance with evidence-based Clinical Practice Guidelines (CPGs) can reduce medical errors and improve patient-centered outcomes. The inferences made by probabilistic machine learning algorithms for diagnosis, prognosis, and treatment are really decision nodes in sometimes long-running clinical processes that implement these CPGs. Long-running processes are referred to as sagas in software engineering parlance.
A system-level approach to AI implementation is required to support clinicians’ workflows and the patient journey. Clinical decision making is about arguing from the evidence. We discuss how CPGs, machine learning inferences, patient preferences, and the available scientific evidence can be reconciled through shared decision making and an argumentation approach.
Furthermore, AI will not reach its full potential unless system-level reforms are implemented in healthcare delivery. The transition from a fee-for-service to a value-based care model; price transparency; and accountable and learning care organizations are examples of needed reforms.
Medical Errors: Errare humanum est
Unwarranted variations from CPGs and medical errors are persisting challenges. In a report by the Agency for Healthcare Research and Quality (AHRQ) titled Diagnostic Errors in the Emergency Department: A Systematic Review, [6] Newman-Toker et al. write:
“We estimate that among 130 million emergency department (ED) visits per year in the United States that 7.4 million (5.7%) patients are misdiagnosed, 2.6 million (2.0%) suffer an adverse event as a result, and about 370,000 (0.3%) suffer serious harms from diagnostic error.”
In the same study [6], “serious harms” is defined as permanent disability or death including more than 100,000 serious, permanent disabilities and over 250,000 deaths.
Understanding Physician Liability in the use of AI: The Pitfalls of Machine Learning Inferences
A well written CPG has clear visualization of decision logic, strength of the evidence, and considerations for comorbidities, shared decision-making, and patient preferences. On the other hand, the inferences made by machine learning algorithms for diagnosis, prognosis, and treatment are probabilistic and non-deterministic in nature.
In the context of Machine Learning, dataset and covariate shifts [28] can produce incorrect and unreliable predictions when the model training and deployment environments differ due to population, equipment, policy, or practice variations [31, 32]. Out-of-distribution (OOD) inputs and the lack of causal inference [29, 30] can result in incorrect predictions as well. Uncertainty quantification is therefore necessary for safe use.
For example, analyses of AI systems designed to detect COVID-19 during the pandemic revealed that some of theses systems rely on spurious correlations or “shortcuts” in the datasets as opposed to medical pathology and failed when tested in new hospital environments [34, 35, 36].
In their paper titled Potential liability for physicians using artificial intelligence [24], Price et al. state:
“Under current law, a physician faces liability only when she or he does not follow the standard of care and an injury results.”
Please refer to [33] for an explanation of the relationship and subtle differences between CPGs and the legal concept of “the standard of care.”
At the time of writing, we are not aware of any legal case involving physician liability in the use of large language models (LLMs) like ChatGPT. However, there have been cases of lawyers submitting incorrect or fictitious cases generated by ChatGPT.
Lawyers from a New York law firm who submitted fake cases generated by ChatGPT have been sanctioned by a judge in June 2023 who said ethics rules “impose a gatekeeping role on attorneys to ensure the accuracy of their filings” [51].
In another case, a Colorado lawyer filed a motion with ChatGPT citing incorrect or fictitious cases. From People v. Zachariah C. Crabill [52] released on November 22, 2023:
“The Presiding Disciplinary Judge approved the parties’ stipulation to discipline and suspended Zachariah C. Crabill (attorney registration number 56783) for one year and one day, with ninety days to be served and the remainder to be stayed upon Crabill’s successful completion of a two year period of probation, with conditions. The suspension took effect November 22, 2023” [52].
In a paper titled Do malpractice claim clinical case vignettes enhance diagnostic accuracy and acceptance in clinical reasoning education during GP training? [58], van Sassen et al. write:
“Malpractice claims could add situativity to CRE [clinical reasoning education] by enriching and supplementing the CR [clinical reasoning] curriculum for advanced learners with a variety of clinical case examples with atypical disease presentations and complex contextual factors, thereby expanding illness scripts in physicians' minds and improving diagnostic performance.”
Situativity [59] is a concept from ecological psychology which emphasizes the study of cognition while the agent is interacting with its natural real-world environment (the umwelt) and with other agents. Situativity is also related to embodiment and affordances. Today's LLMs like ChatGPT are disembodied.
Sagas, the Patient Journey, and Patient-Centered Outcomes
The Saga Pattern is an enterprise integration pattern for distributed transactions and Microservices [9] spanning multiple services within and across organizational boundaries. In software engineering, Design Patterns are very helpful as proven blueprints of best practices. Domain-agnostic notations like the Decision Model and Notation (DMN) and the Business Process Model and Notation (BPMN) have been explored for modeling clinical decisions and workflows.
The following is a Decision Requirements Diagram (DRD) for a colorectal cancer (CRC) treatment decision model using the DMN [44]. Clinical decisions are represented as nodes within clinical workflows. The latter can be modelled with BPMN. A Business Knowledge Model can be a clinical rule from a CPG, a policy, the output of a machine learning inference, or some other scientific evidence.
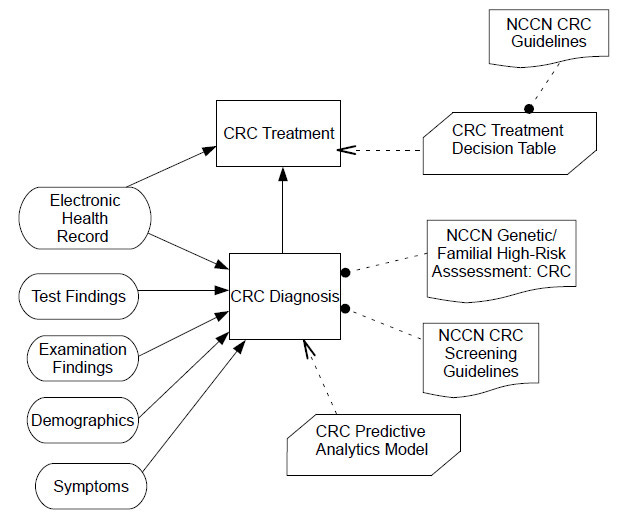
In the context of health information exchange (HIE) across healthcare organizations (hospitals, outpatient clinics, health insurers, etc.), standards like the HL7 Consolidated Clinical Document Architecture (CCDA); the Fast Healthcare Interoperability Resources (FHIR); and Integrating the Healthcare Enterprise (IHE) Cross-Enterprise Document Sharing (XDS) are used.
Patients’ financial difficulties [54, 55, 56, 57] in the absence of universal healthcare and health insurers’ refusal to reimburse healthcare providers for patient care can complicate the patient journey. According to [54], 100 million people in America are affected by health care debt. Debt collection is now a profitable business for some [56].
Unfortunately, algorithmic decision making can also be used to deny health insurance claims or enable the inequitable allocation of healthcare resources [25, 46].
Furthermore, there is an increasing awareness of the social, economic, and environmental determinants of human health. Patient-centered outcomes include essential measures such as survival, time to recovery, severity of side effects, quality of life, functional status, and remission.
A focus on the patient journey starts with prevention and early detection.
The Exposomics, Prevention, and Early Detection
With the discovery of new biomarkers from imaging, genomics, transcriptomics, epigenomics, proteomics, metabolomics, microbiomics, and other -omics, the number of data types that should be considered in clinical decision making will quickly surpass the information processing capacities of the human brain [2]. The emerging concept of exposomics aims to assess the health impact of environmental exposures and pollutants [3].
According to Lecia Vandam Sequist, M.D., Landry Family Professor of Medicine at Harvard Medical School and the Program Director of the Cancer Early Detection and Diagnostics Clinic at Mass General Cancer Center:
“Lung cancer rates continue to rise among people who have never smoked or who haven’t smoked in years, suggesting that there are many risk factors contributing to lung cancer risk, some of which are currently unknown [8]”.
Humans, animals, and plants are holobionts — a collection of diverse species (cells, bacteria, viruses) with complex interaction networks having a role in health and disease [12]. We are yet to fully understand the evolutionary biology of cancer cells [10]. Therefore, emphasis will need to be on early detection and prevention. Progress is being made in using Deep Learning for prognosis of future lung cancer risk [11]. Randomized Control Trials (RCTs) of these algorithmic interventions will accelerate their translation into routine clinical practice.
Learning from the History of AI ChatBots in Healthcare
Lessons must be learned from Babylon Health, the maker of an AI chatbot who won an NHS contract to revolutionize healthcare in UK. Babylon Health also signed a 10-year partnership with the government of Rwanda to deliver virtual primary care services with a $2.2 million grant from the Bill & Melinda Gates Foundation.
Babylon Health was valued at over $4 billion when it went public in 2021. It has collapsed and declared bankruptcy two years later [23] and also shut down its operations in Rwanda. Success in healthcare is built on scientific evidence, long term dedication, and trust, not hype.
Before Babylon Health, IBM Watson Health was sold off in parts for a billion in 2021 after the company spent over $5 billion dollar in acquisitions and a marketing campaign promising an AI revolution in healthcare that never materialized [45].
Assurance Cases: Arguing for Regulatory Certification and Patient Safety
In a paper titled Large language model AI chatbots require approval as medical devices [15] published in the journal Nature Medicine in June 2023, Gilbert et al. write:
“Chatbots powered by artificial intelligence used in patient care are regulated as medical devices, but their unreliability precludes approval as such.”
We concur with their view. Refer to [53] for a perspective from the UK Medicines and Healthcare products Regulatory Agency.
Traditional medical device regulation standards are very prescriptive in nature. They have been very effective in the certification and safety of deterministic systems. Systems based on Machine Learning present novel challenges that may be better handled through a safety argumentation approach. Assurance Cases are a methodology created by John Rushby who defined it as follows [38]:
“Assurance cases are a method for providing assurance for a system by giving an argument to justify a claim about the system, based on evidence about its design, development, and tested behavior.”
Assurance Cases provide a framework for an adaptive and agile approach to regulatory certification.
Clinical Reasoning in CPGs and Machine Learning Algorithms
An example of a well-written CPG is the Diabetes Management in Chronic Kidney Disease: Synopsis of the KDIGO 2022 Clinical Practice Guideline Update [7].
Decades before the Deep Learning revolution circa 2012, the field of Medical Informatics has produced a number of formalisms for representing the medical knowledge in CPGs in the form of computer-interpretable clinical guidelines (CIGs). Examples of CIGs formalisms include GLIF, Arden, PROforma, and EON. Interoperability standards like HL7 are essential as well.
Certain types of decision nodes require the automated execution of highly accurate and precise calculations and decision logic over multiple clinical concept codes (e.g., SNOMED codes) and numeric values (e.g., lab results) which are better performed with a logic-based formalism like First-Order logic (FOL), Constraint Logic Programming, or non-monotonic reasoning with Answer-Set Programming (ASP).
For example, the KDIGO 2022 Clinical Practice Guideline for Diabetes Management in Chronic Kidney Disease [7] contains the following decision logic:
“Metformin may be given when estimated glomerular filtration rate (eGFR) $30 ml/min per 1.73 m2 , and SGLT2i should be initiated when eGFR is $20 ml/min per 1.73 m2 and continued as tolerated, until dialysis or transplantation is initiated.”
Biomedical ontologies and standardized code sets such as LOINC, RxNorm, and SNOMED are used for semantic interoperability. For example, metformin is a drug with code “6809” in RxNorm. Description Logic (DL) is the foundation of the Systematized Nomenclature of Medicine (SNOMED) — an ontology which contains more than 300,000 carefully curated medical concepts organized into a class hierarchy and enabling automated reasoning capabilities based on subsumption and attribute relationships between medical concepts.
The jury is still out about the reasoning abilities of Deep Learning. French mathematician Jacques Hadamard (1865-1963) remarked that “logic merely sanctions the conquests of the intuition.” Previous efforts like Statistical Relational Learning (SRL) and Neuro-Symbolic AI combined logic and statistical learning for sophisticated reasoning.
Deep Learning algorithms are uninterpretable black boxes, so it is difficult to understand their reasoning processes. De Graves et al. [37] combines explainable AI and generative AI methods to provide a medically interpretable explanation of the reasoning processes of dermatology AI algorithms.
Reasoning and Planning in Large Language Models (LLMs)
Autoregressive LLMs are statistical next-token predictors in Internet-scale text corpora. On the other hand, safe AI requires factuality, causality, reasoning, and planning. Recent papers did a good job at probing the inner workings of LLMs and shedding some light on their limitations in these areas.
In [39], McCoy et al. elaborate on what they call “embers of autoregression” in LLMs after the “Sparks of AGI” [40]:
“a. Sensitivity to task frequency
b. Sensitivity to output probability
c. Sensitivity to input probability
d. Lack of embodiment
e. Sensitivity to wording
f. Difficulty on meaning-dependent tasks
g. Inability to modify text that has already been produced
h. Societal biases and spurious correlations
i. Idiosyncratic memorization
j. Sensitivity to tokenization
k. Limited compositionality and systematicity.”
In [41], Wu et al. note a significant performance degradation when LLMs are asked counterfactual variants of questions on which they previously performed well, pointing to overfitting, memorization, and a lack of causal reasoning.
In [42], Kambhampati concludes that “nothing that I have read, verified or done gives me any compelling reason to believe that LLMs do reasoning/planning as it is normally understood”.
In [43], Valmeekam et al. report that on a planning benchmark similar to the ones used in the International Planning Competition, GPT-4 was the best performer among LLMs with an average success rate of ~12%.
Validation and Verification (V&V) of Clinical AI
The accuracy and reliability of AI clinical prediction models depend on the quality of the clinical data in electronic medical record (EMR) systems. Measurement errors and misclassification can have a negative impact on model quality. A study of EMR data at the University of Pennsylvania Medical Center More found that 50.1% of the clinical notes were duplicated from prior documentation through copy-and-paste [13]. Inaccurate clinical information in the EMR puts patient safety at risk [26].
In general, the data in the EMR is not always an objective and accurate assessment and representation of the underlying disease biology. Using the documentation of stroke in the EMR as an example, Mullainathan and Obermeyer write [14]:
“We have spoken as if we are predicting ‘stroke.’ Yet our measures are several layers removed from the biological signature of blood flow restriction to brain cells. Instead we see the presence of a billing code or a note recorded by a doctor.”
One lesson we have learned from studying the introduction of AI in medicine during the last decade is that the responsible use of AI requires not only validation and verification but also prospective studies (randomized controlled trials or RCTs)to evaluate the efficacy of AI on patient-centered outcomes. The recently released guidelines for clinical trial protocols for interventions involving artificial intelligence (SPIRIT-AI) and the guidelines for clinical trial reports for interventions involving artificial intelligence (CONSORT-AI) represent significant milestones for evidence-based AI in healthcare.
The introduction of predictive models into clinical practice requires rigorous validation. Internal validation using methods like cross-validation or preferably the Bootstrap should provide clear performance measures such as discrimination (e.g., C-statistic or D-statistic) and calibration (e.g., calibration-in-the-large and calibration slope). In addition to internal validation, external validation should be performed as well to determine the generalizability of the model to other patient populations. External validation can be performed with data collected at a different time (temporal validation) or at different locations, countries, or clinical settings (geographic validation). The clinical usefulness of the prediction model (net benefit) can be evaluated using decision curve analysis.
Consensus guidelines for the development of clinical prediction models include:
The Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis (TRIPOD) Statement.
The Reporting guideline for the early-stage clinical evaluation of decision support systems driven by artificial intelligence: DECIDE-AI.
The Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis–AI (TRIPOD-AI).
The Standards For Reporting Diagnostic Accuracy Studies–Artificial Intelligence (STARD-AI).
Traditional statistical validation approaches like cross-validation and the Bootstrap perform validation using data from the same clinical data set used for training the algorithm. This data set is typically collected during routine clinical care and stored in an electronic health records system or an imaging database. On the other hand, formal methods can generate counterexamples such as out-of-distribution (OOD) and adversarial inputs which can result in incorrect predictions. There is a growing literature on the use of formal methods based on probabilistic verification for providing provable guarantees of the robustness, safety, and fairness of Machine Learning algorithms.
Principled approaches should be used for handling missing data and for representing the uncertainty inherent in clinical data including measurement errors and misclassification. Bayesian Decision Theory is a principled methodology for solving decision-making problems under uncertainty. We see the Bayesian approach as a promising alternative to null hypothesis significance testing (using statistical significance thresholds like the p-value) which has contributed to the current replication crisis in biomedicine.
Furthermore, clinicians sometimes need answers to counterfactual questions at the point of care (e.g., when estimating the causal effect of a clinical intervention). We believe that these questions are best answered within the framework of Causal Inference as opposed to prediction with Machine Learning. It is a well-known adage that correlation does not imply causation. Causal models are also more robust to dataset shifts than predictive models and better reflect the underlying biology of disease.
The outputs of AI algorithms are probabilistic and non-deterministic in nature and the ability to quantify and understand uncertainties will be essential for safety-critical operations, particularly when human life is at stake. Out-of-distribution (OOD) inputs are a particular concern and require proper handling during operations. Conformal Prediction is a method that can produce uncertainty sets or intervals of the model's predictions with guarantees based on probabilities that can be specified by the user.
Dynamic Treatment Regimes (as opposed to static rule-based CPGs) is an approach with roots in Reinforcement Learning which can be used to personalize sequential treatment decisions based on the individual patient’s disease trajectory and up-to-date clinical data.
Clinical Evaluation of LLMs and Privacy Concerns
If used responsibly, recent advances in large language models (LLMs) and Clinical Question Answering can help. If not, by embedding Generative AI into the EMR, there is a risk that patient's clinical data will be further polluted by inaccurate and fabricated content including misdiagnosis. There is also a privacy risk with clinicians submitting patient data to ChatGPT and similar services. Companies including Northrop Grumman, Apple, JPMorgan Chase, Samsung, Wells Fargo, and Bank Of America have banned or restricted access to ChatGPT for their employees at work because of cybersecurity and privacy concerns [27].
Clinical evaluation standards for online symptom checkers will certainly be needed given the excitement about chatbots like ChatGPT [4,5].
MedAlign, a benchmark dataset of 983 natural language instructions for EMR data curated by clinicians found error rates in LLM responses ranging from 35% for GPT-4 to 68% for MPT-7B-Instruct [19].
In another study [20], one-third of treatment recommendations made by GPT-3.5-turbo0301 for breast, prostate, and lung cancer treatment were non-concordant with NCCN guidelines.
As the EMR gets populated with generated data over time, it will also become less reliable and effective as a source for training future AI models, not only because of inaccurate clinical data, but also because of a phenomenon known as Model Collapse [21], aka the Curse of Recursion [21], or Model Autophagy Disorder (MAD) [22].
Arguing From the Evidence in Clinical Decision Making
Medical decision making can be very complex. Clinical decision making is about arguing from the evidence. One major concern with ChatGPT is that it does not reveal the sources of its recommendations or sometimes generate fake citations to documents that don’t exist [15].
In their paper titled Why do humans reason? Arguments for an argumentative theory [18], Hugo Mercier and Dan Sperber write:
“Our hypothesis is that the function of reasoning is argumentative. It is to devise and evaluate arguments intended to persuade.”
The framework of shared decision-making [50] considers the values, goals, and preferences of the patient. Argumentation Theory [47, 48, 49] is a good old branch of AI that can help reconcile probabilistic machine learning inferences, uncertainty, risks and benefits, patient preferences, CPGs, and other scientific evidence from the peer-reviewed biomedical literature.
References:
[1] Johansson, Minna, Gordon Guyatt, and Victor Montori. "Guidelines should consider clinicians’ time needed to treat." bmj 380 (2023).
[2] Shen, Xiaotao, Ryan Kellogg, Daniel J. Panyard, Nasim Bararpour, Kevin Erazo Castillo, Brittany Lee-McMullen, Alireza Delfarah et al. "Multi-omics microsampling for the profiling of lifestyle-associated changes in health." Nature Biomedical Engineering (2023): 1-19.
[3] Wu, Haotian, Christina M. Eckhardt, and Andrea A. Baccarelli. "Molecular mechanisms of environmental exposures and human disease." Nature Reviews Genetics (2023): 1-13.
[4] Painter, Annabelle, Benedict Hayhoe, Eva Riboli-Sasco, and Austen El-Osta. "Online Symptom Checkers: Recommendations for a Vignette-Based Clinical Evaluation Standard." Journal of medical Internet research 24, no. 10 (2022): e37408.
[5] Wallace, William, Calvin Chan, Swathikan Chidambaram, Lydia Hanna, Fahad Mujtaba Iqbal, Amish Acharya, Pasha Normahani et al. "The diagnostic and triage accuracy of digital and online symptom checker tools: a systematic review." NPJ digital medicine 5, no. 1 (2022): 1-9.
[6] Newman-Toker, David E., Susan M. Peterson, Shervin Badihian, Ahmed Hassoon, Najlla Nassery, Donna Parizadeh, Lisa M. Wilson et al. "Diagnostic Errors in the Emergency Department: A Systematic Review." (2022).
[7] Navaneethan, Sankar D., Sophia Zoungas, M. Luiza Caramori, Juliana CN Chan, Hiddo JL Heerspink, Clint Hurst, Adrian Liew et al. "Diabetes Management in Chronic Kidney Disease: Synopsis of the KDIGO 2022 Clinical Practice Guideline Update." Annals of Internal Medicine (2023).
[8] “AI Tool Predicts Risk of Lung Cancer” https://hms.harvard.edu/news/ai-tool-predicts-risk-lung-cancer
[9] "Pattern: Saga" by Chris Richardson https://microservices.io/patterns/data/saga.html
[10] Al Bakir, M., Huebner, A., Martínez-Ruiz, C. et al. The evolution of non-small cell lung cancer metastases in TRACERx. Nature (2023). https://www.nature.com/articles/s41586-023-05729-x
[11] Mikhael, Peter G., Jeremy Wohlwend, Adam Yala, Ludvig Karstens, Justin Xiang, Angelo K. Takigami, Patrick P. Bourgouin et al. "Sybil: a validated deep learning model to predict future lung cancer risk from a single low-dose chest computed tomography." Journal of Clinical Oncology (2023): JCO-22. https://ascopubs.org/doi/full/10.1200/JCO.22.01345
[12] Eric Topol, "The fascinating and evolving story of bacteria and cancer"

[13] Steinkamp, Jackson, Jacob J. Kantrowitz, and Subha Airan-Javia. "Prevalence and sources of duplicate information in the electronic medical record." JAMA Network Open 5, no. 9 (2022): e2233348-e2233348.
[14] Mullainathan, Sendhil, and Ziad Obermeyer. "Does machine learning automate moral hazard and error?." American Economic Review 107, no. 5 (2017): 476-480.
[15] Gilbert, Stephen, Hugh Harvey, Tom Melvin, Erik Vollebregt, and Paul Wicks. "Large language model AI chatbots require approval as medical devices." Nature Medicine (2023): 1-3.
[16] Cigna accused of using an algorithm to reject patients' health insurance claims https://www.cbsnews.com/news/cigna-algorithm-patient-claims-lawsuit/
[17] How Cigna Saves Millions by Having Its Doctors Reject Claims Without Reading Them https://www.propublica.org/article/cigna-pxdx-medical-health-insurance-rejection-claims
[18] Mercier, Hugo, and Dan Sperber. "Why do humans reason? Arguments for an argumentative theory." Behavioral and brain sciences 34, no. 2 (2011): 57-74.
[19] Fleming, Scott L., Alejandro Lozano, William J. Haberkorn, Jenelle A. Jindal, Eduardo P. Reis, Rahul Thapa, Louis Blankemeier et al. "MedAlign: A Clinician-Generated Dataset for Instruction Following with Electronic Medical Records." arXiv preprint arXiv:2308.14089 (2023).
[20] Chen, Shan, Benjamin H. Kann, Michael B. Foote, Hugo JWL Aerts, Guergana K. Savova, Raymond H. Mak, and Danielle S. Bitterman. "Use of Artificial Intelligence Chatbots for Cancer Treatment Information." JAMA oncology (2023).
[21] Shumailov, Ilia, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. "The Curse of Recursion: Training on Generated Data Makes Models Forget." arXiv preprint arxiv:2305.17493 (2023).
[22] Alemohammad, Sina, Josue Casco-Rodriguez, Lorenzo Luzi, Ahmed Imtiaz Humayun, Hossein Babaei, Daniel LeJeune, Ali Siahkoohi, and Richard G. Baraniuk. "Self-consuming generative models go mad." arXiv preprint arXiv:2307.01850 (2023).
[23] Grace Browne, "The Fall of Babylon Is a Warning for AI Unicorns." WIRED, Sep 19. 2023, https://www.wired.com/story/babylon-health-warning-ai-unicorns/
[24] Price, W. Nicholson, Sara Gerke, and I. Glenn Cohen. "Potential liability for physicians using artificial intelligence." Jama 322, no. 18 (2019): 1765-1766.
[25] Obermeyer, Ziad, Brian Powers, Christine Vogeli, and Sendhil Mullainathan. "Dissecting racial bias in an algorithm used to manage the health of populations." Science 366, no. 6464 (2019): 447-453.
[26] Sandeep Jauhar, "Bloated patient records are filled with false information, thanks to copy-paste," STAT News, June 20, 2023 https://www.statnews.com/2023/06/20/medical-records-errors-copy-paste/
[27] Aaron Mok, "Amazon, Apple, and 12 other major companies that have restricted employees from using ChatGPT." Business Insider, Jul 11, 2023. https://www.businessinsider.com/chatgpt-companies-issued-bans-restrictions-openai-ai-amazon-apple-2023-7
[28] Finlayson, Samuel G., Adarsh Subbaswamy, Karandeep Singh, John Bowers, Annabel Kupke, Jonathan Zittrain, Isaac S. Kohane, and Suchi Saria. "The clinician and dataset shift in artificial intelligence." New England Journal of Medicine 385, no. 3 (2021): 283-286.
[29] Castro, Daniel C., Ian Walker, and Ben Glocker. "Causality matters in medical imaging." Nature Communications 11, no. 1 (2020): 3673.
[30] Subbaswamy, Adarsh, Bryant Chen, and Suchi Saria. "A unifying causal framework for analyzing dataset shift-stable learning algorithms." Journal of Causal Inference 10, no. 1 (2022): 64-89.
[31] Agniel, Denis, Isaac S. Kohane, and Griffin M. Weber. "Biases in electronic health record data due to processes within the healthcare system: retrospective observational study." Bmj 361 (2018).
[32] Zech, John R., Marcus A. Badgeley, Manway Liu, Anthony B. Costa, Joseph J. Titano, and Eric Karl Oermann. "Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: a cross-sectional study." PLoS medicine 15, no. 11 (2018): e1002683.
[33] Cooke, Brian K., Elizabeth Worsham, and Gary M. Reisfield. "The elusive standard of care." J Am Acad Psychiatry Law 45, no. 3 (2017): 358-364.
[34] DeGrave, Alex J., Joseph D. Janizek, and Su-In Lee. "AI for radiographic COVID-19 detection selects shortcuts over signal." Nature Machine Intelligence 3, no. 7 (2021): 610-619.
[35] Roberts, Michael, Derek Driggs, Matthew Thorpe, Julian Gilbey, Michael Yeung, Stephan Ursprung, Angelica I. Aviles-Rivero et al. "Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans." Nature Machine Intelligence 3, no. 3 (2021): 199-217.
[36] DeGrave, Alex J., Joseph D. Janizek, and Su-In Lee. "Course Corrections for Clinical AI." Kidney360 2, no. 12 (2021): 2019.
[37] DeGrave, Alex J., Zhuo Ran Cai, Joseph D. Janizek, Roxana Daneshjou, and Su-In Lee. "Dissection of medical AI reasoning processes via physician and generative-AI collaboration." medRxiv (2023).
[38] Rushby, John. "The interpretation and evaluation of assurance cases." Comp. Science Laboratory, SRI International, Tech. Rep. SRI-CSL-15-01 (2015).
[39] McCoy, R. Thomas, Shunyu Yao, Dan Friedman, Matthew Hardy, and Thomas L. Griffiths. "Embers of Autoregression: Understanding Large Language Models Through the Problem They are Trained to Solve." arXiv preprint arXiv:2309.13638 (2023).
[40] Bubeck, Sébastien, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee et al. "Sparks of artificial general intelligence: Early experiments with gpt-4." arXiv preprint arXiv:2303.12712 (2023).
[41] Wu, Zhaofeng, Linlu Qiu, Alexis Ross, Ekin Akyürek, Boyuan Chen, Bailin Wang, Najoung Kim, Jacob Andreas, and Yoon Kim. "Reasoning or reciting? exploring the capabilities and limitations of language models through counterfactual tasks." arXiv preprint arXiv:2307.02477 (2023).
[42] Subbarao Kambhampati, September 12, 2023, "Can LLMs Really Reason and Plan?" In Communications of the ACM
[43] Valmeekam, Karthik, Matthew Marquez, Sarath Sreedharan, and Subbarao Kambhampati. "On the Planning Abilities of Large Language Models--A Critical Investigation." arXiv preprint arXiv:2305.15771 (2023).
[44] Sylvie Dan, "Eliciting Requirements for Clinical Decision Support (CDS) Systems" April 5, 2015. https://www.linkedin.com/pulse/eliciting-requirements-clinical-decision-support-cds-dan-ccba-pmp/
[45] LIZZIE O’LEARY. "How IBM’s Watson Went From the Future of Health Care to Sold Off for Parts." JAN 31, 2022. https://slate.com/technology/2022/01/ibm-watson-health-failure-artificial-intelligence.html
[46] Casey Ross and Bob Herman. "Denied by AI: How Medicare Advantage plans use algorithms to cut off care for seniors in need" STAT News, March 13, 2023 https://www.statnews.com/2023/03/13/medicare-advantage-plans-denial-artificial-intelligence
[47] Hunter, Anthony, and Matthew Williams. "Argumentation for aggregating clinical evidence." In 2010 22nd IEEE International Conference on Tools with Artificial Intelligence, vol. 1, pp. 361-368. IEEE, 2010.
[48] A. Hunter, S. Polberg, N. Potyka, T. Rienstra, M. Thimm, Probabilistic argumentation: a survey, in: Handbook of Formal Argumentation, vol. 2, 2021, pp. 397–441.
[49] Longo, Luca, and Lucy Hederman. "Argumentation theory for decision support in health-care: A comparison with machine learning." In International conference on brain and health informatics, pp. 168-180. Cham: Springer International Publishing, 2013.
[50] Stiggelbout, Anne M., Trudy Van der Weijden, Maarten PT De Wit, Dominick Frosch, France Légaré, Victor M. Montori, Lyndal Trevena, and Glenn Elwyn. "Shared decision making: really putting patients at the centre of healthcare." Bmj 344 (2012).
[51] Sara Merken. "New York lawyers sanctioned for using fake ChatGPT cases in legal brief." Reuters, June 26, 2023. https://www.reuters.com/legal/new-york-lawyers-sanctioned-using-fake-chatgpt-cases-legal-brief-2023-06-22/
[52] People v. Zachariah C. Crabill. 23PDJ067. November 22, 2023. https://coloradosupremecourt.com/PDJ/Decisions/Crabill,%20Stipulation%20to%20Discipline,%2023PDJ067,%2011-22-23.pdf
[53] Johan Ordish. "Large Language Models and software as a medical device." 3 March 2023. https://medregs.blog.gov.uk/2023/03/03/large-language-models-and-software-as-a-medical-device/
[54] 100 Million People in America Are Saddled With Health Care Debt (KFF Health News) https://kffhealthnews.org/news/article/diagnosis-debt-investigation-100-million-americans-hidden-medical-debt/
[55] Trapped: America’s Crippling Medical Debt Crisis (RIP Medical Debt) https://ripmedicaldebt.org/trapped-americas-crippling-medical-debt-crisis/
[56] Debt Collection in American Medicine — A History (NEJM) https://www.nejm.org/doi/full/10.1056/NEJMms2308571
[57] Preventing Medical Debt From Disrupting Health and Financial Health – Recommendations for Hospitals and Health Systems (Financial Health Network) https://finhealthnetwork.org/wp-content/uploads/2022/03/Medical-Debt-and-Financial-Health-For-Hospitals-and-Care-Systems.pdf
[58] van Sassen, Charlotte, et al. "Do malpractice claim clinical case vignettes enhance diagnostic accuracy and acceptance in clinical reasoning education during GP training?." BMC Medical Education 23.1 (2023): 1-11.
[59] Merkebu, Jerusalem, et al. "Situativity: a family of social cognitive theories for understanding clinical reasoning and diagnostic error." Diagnosis 7.3 (2020): 169-176.